Integration von Large Language Models (LLMs) 2025: Ein umfassender Leitfaden für Entwickler
Praktischer Leitfaden für AI-assistierte Entwicklung mit GitHub Copilot und Cursor. Setup, Best Practices, Vergleich und Produktivitäts-Tipps für deutsche Entwickler 2025.

Large Language Models (LLMs) revolutionieren die Softwareentwicklung und ermöglichen innovative Anwendungen mit menschenähnlichen Sprachfähigkeiten. Dieser umfassende Leitfaden zeigt Entwicklern, wie sie OpenAI und Anthropic Claude APIs effektiv integrieren, fortschrittliches Prompt Engineering beherrschen und Kosten optimieren können.
OpenAI API Integration: Von Grundlagen bis zur Implementierung
Was ist die OpenAI API?
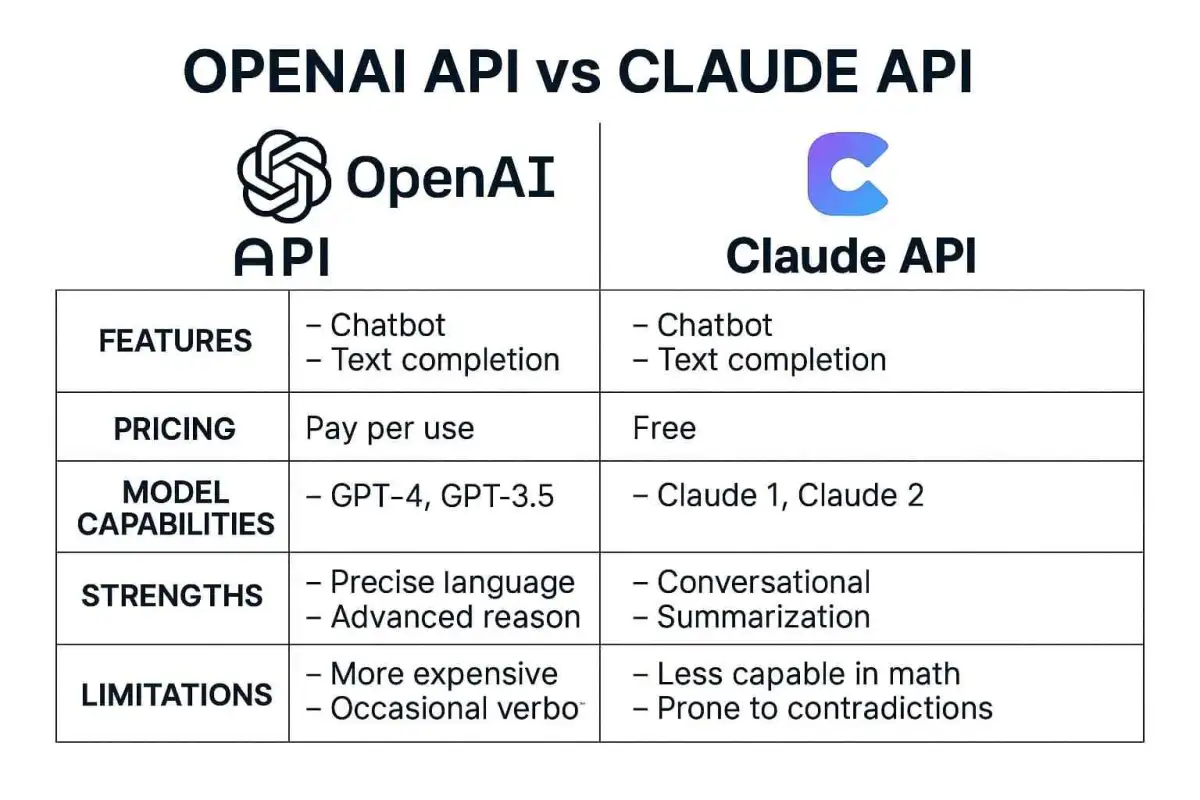
Die OpenAI API bietet Entwicklern Zugang zu leistungsstarken Sprachmodellen wie GPT-4.5 und o1, die Textverstehen, -generierung und multimodale Fähigkeiten ermöglichen. Als Gateway zu den fortschrittlichsten KI-Modellen erlaubt die API die Integration dieser Funktionen in eigene Anwendungen durch einfache HTTP-Requests.
Neue Features 2025
Responses API mit Remote MCP-Server-Unterstützung: OpenAI hat 2025 die Responses API mit Unterstützung für Remote Model Context Protocol (MCP) Server erweitert, was die Integration mit externen Diensten erheblich verbessert. Diese Funktion ermöglicht agentenbasierte Anwendungen mit verbesserter Kontextverarbeitung.
Bild- und Codegenerierung: Die neuesten Updates bieten erweiterte Funktionen für Bildgenerierung und Code Interpreter direkt über die API, was die Entwicklung multifunktionaler Anwendungen vereinfacht.
Background Mode: Für rechenintensive Aufgaben führte OpenAI einen asynchronen Background-Modus ein, der lange Operationen zuverlässiger abwickelt und bessere Kontrolle über komplexe Workflows bietet.
Erste Schritte mit der OpenAI API
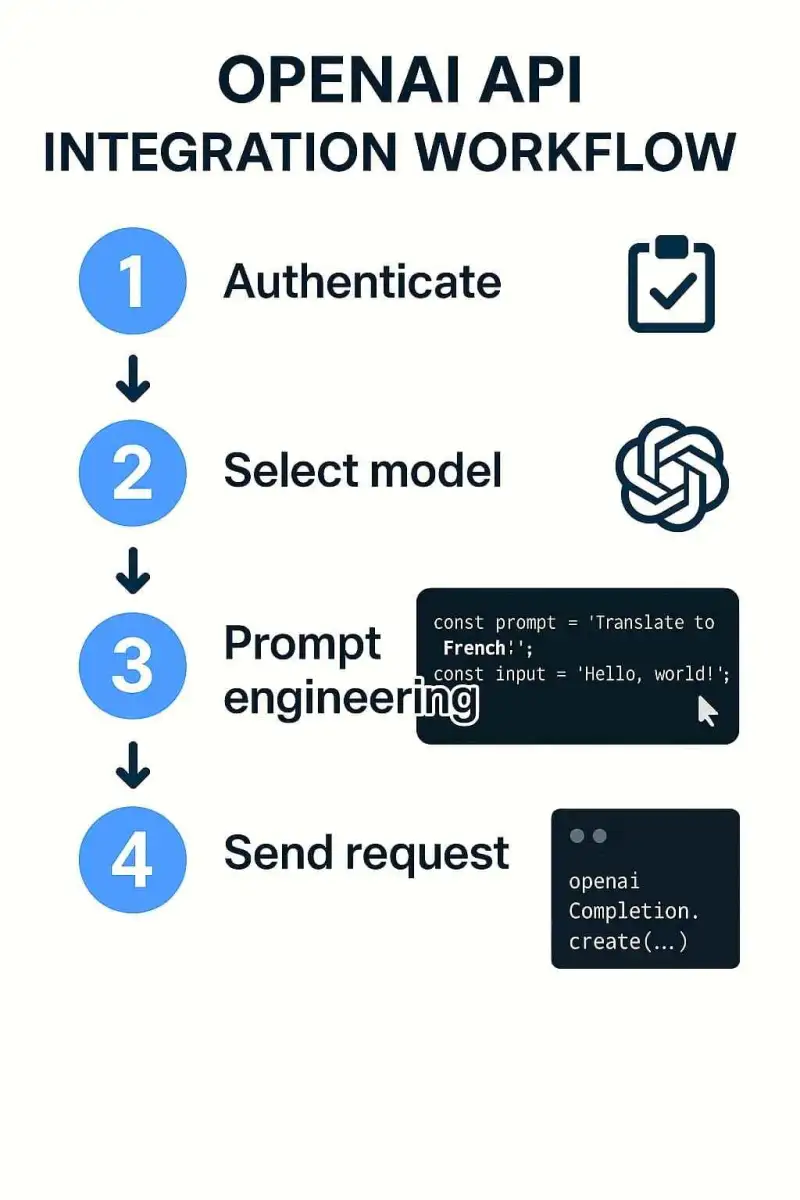
Voraussetzungen
- OpenAI API-Konto und API-Schlüssel
- Grundlegende Programmierkenntnisse (Python, JavaScript etc.)
- Verständnis von REST APIs und JSON
# OpenAI API Basisintegration
import os
from openai import OpenAI
# Client initialisieren
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
# Anfrage an das Modell senden
response = client.chat.completions.create(
model="gpt-4.5",
messages=[
{"role": "system", "content": "Du bist ein hilfreicher Assistent."},
{"role": "user", "content": "Erkläre mir die Vorteile von APIs in einfachen Worten."}
]
)
# Antwort ausgeben
print(response.choices[0].message.content)Anthropic Claude API: Die innovative Alternative
Was ist die Claude API?
Die Anthropic Claude API bietet Zugang zu den Claude-Sprachmodellen, die für ihre Sicherheitsausrichtung, natürliches Verständnis und nuancierte Textgenerierung bekannt sind. Claude zeichnet sich besonders durch längere Konversationen, bessere Kontextverarbeitung und die Fähigkeit, komplexe Aufgaben zu bewältigen, aus.
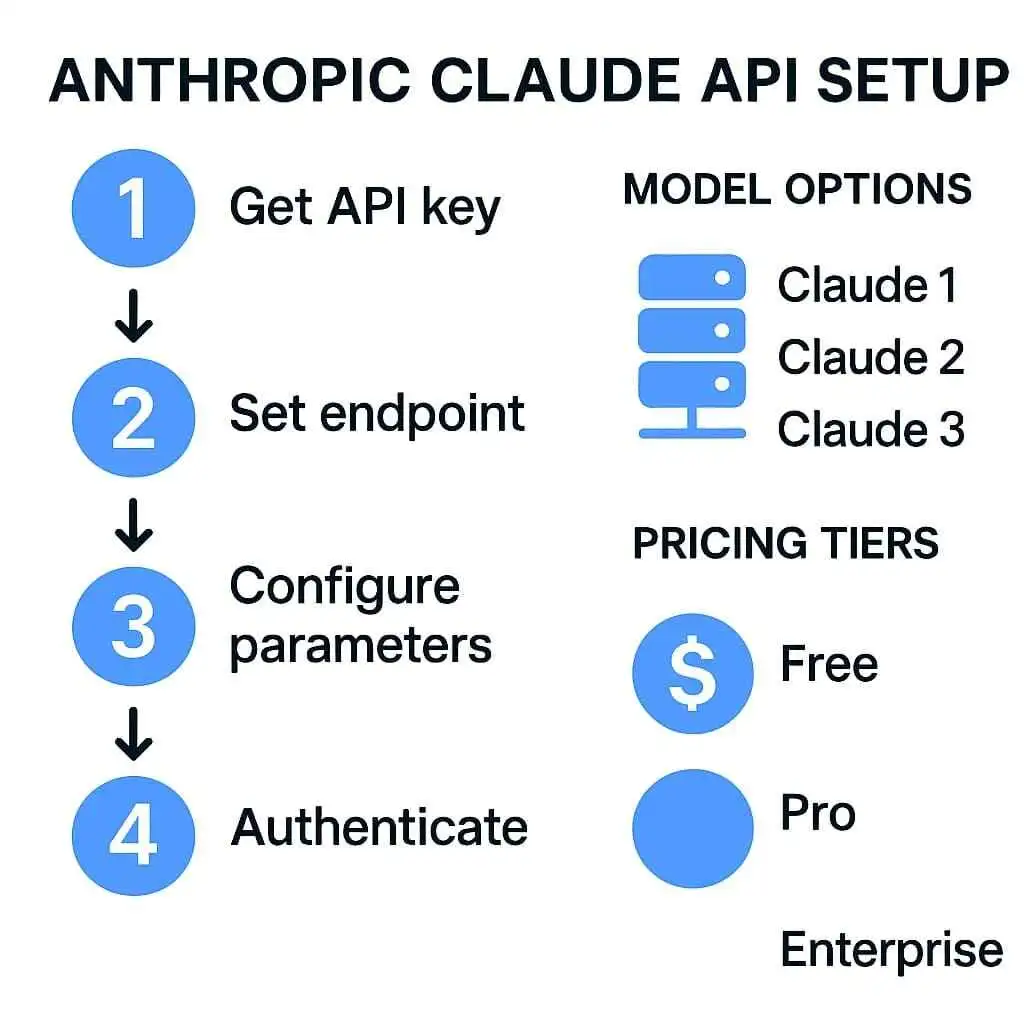
Claude-Modelle im Überblick
- Claude 4 Opus: Das leistungsstärkste Modell mit überragenden Reasoning-Fähigkeiten, ideal für komplexe Aufgaben
- Claude 4 Sonnet: Ausgewogenes Modell mit guter Balance zwischen Leistung und Geschwindigkeit für allgemeine Unternehmensanwendungen
- Claude 3.5 Haiku: Schnellstes und kosteneffizientestes Modell für Anwendungen mit hohem Durchsatz
# Claude API Basisintegration
import os
import anthropic
# Client initialisieren
client = anthropic.Anthropic(
api_key=os.environ.get("ANTHROPIC_API_KEY")
)
# Anfrage an Claude senden
message = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=1024,
messages=[
{"role": "user", "content": "Erkläre mir die Vorteile von AI-Integrationen für Entwickler."}
]
)
# Antwort ausgeben
print(message.content[0].text)Prompt Engineering für Entwickler
Grundlagen des Prompt Engineering
Prompt Engineering ist die Kunst und Wissenschaft, effektive Anweisungen für LLMs zu erstellen, um präzise und relevante Antworten zu erhalten. Es ist ein entscheidender Faktor für erfolgreiche LLM-Integrationen und hat direkten Einfluss auf die Qualität der Ergebnisse und die Kosteneffizienz.
Zero-Shot vs. Few-Shot Prompting
Zero-Shot Prompting ist die einfachste Form des Promptings, bei der dem Modell eine Anweisung oder Frage ohne Beispiele gegeben wird. Dies funktioniert gut für einfache, allgemeine Aufgaben, erfordert aber präzise Formulierungen.
Few-Shot Prompting bietet dem Modell ein oder mehrere Beispiele, wie die gewünschte Ausgabe aussehen soll. Durch die Bereitstellung von Beispielen erhöht sich die Wahrscheinlichkeit, dass das LLM die Aufgabe korrekt und im gewünschten Format löst.
Best Practices für effektives Prompt Engineering
1. Klarer Kontext: Bieten Sie ausreichend Hintergrundinformationen, damit das Modell die Anfrage richtig versteht.
2. Spezifische Anweisungen: Formulieren Sie präzise, was Sie vom Modell erwarten, einschließlich Format, Ton und Umfang.
3. Aufgaben aufteilen: Brechen Sie komplexe Aufgaben in kleinere, besser handhabbare Schritte auf.
4. Iteratives Verfeinern: Starten Sie mit einfachen Prompts und verfeinern Sie diese basierend auf den Ergebnissen.
5. Konsistenz in Formatierung: Verwenden Sie durchgängig dieselbe Formatierung und Struktur in Ihren Prompts.
Kostenoptimierte LLM-Nutzung

> Herausforderungen der LLM-Kostenoptimierung
Die Kosten für LLM-API-Nutzung können schnell ansteigen, besonders bei hohem Anfragevolumen oder komplexen Anwendungen. Hauptkostenfaktoren sind:
- Token-basierte Abrechnung (Input und Output)
- Modellauswahl (größere Modelle = höhere Kosten)
- Kontextfenstergröße (längere Kontexte verbrauchen mehr Token)
- Anfragevolumen und -häufigkeit
Strategie 1: LLM Cascading
LLM Cascading ist eine effektive Strategie, bei der Anfragen durch eine Sequenz von Modellen verarbeitet werden, beginnend mit dem günstigsten Modell und nur bei Bedarf zu leistungsfähigeren Modellen eskalierend. Mit dieser Strategie können Kosteneinsparungen von bis zu 87% erreicht werden, wobei die meisten Anfragen bei günstigeren Modellen verbleiben.
Strategie 2: Prompt-Optimierung und Token-Minimierung
Da LLM-APIs pro Token abrechnen, führt die Reduzierung der Token direkt zu Kosteneinsparungen. Techniken umfassen:
- Prompt-Kompression: Entfernen redundanter Informationen
- Präzise Instruktionen: Klare, direkte Anweisungen statt ausschweifender Erklärungen
- Informationspriorisierung: Wichtige Informationen zuerst, um Wiederholungen zu vermeiden
Strategie 3: Caching und RAG
Semantisches Caching speichert Antworten auf häufige Anfragen in einem Cache, was eine sofortige Abrufung ohne erneute LLM-Anfrage ermöglicht.
Retrieval-Augmented Generation (RAG) ergänzt LLMs mit externen Datenquellen, was den Bedarf an großen Kontextfenstern reduziert und den Token-Verbrauch um bis zu 30% senken kann.
Zusammenfassung und Best Practices
Die erfolgreiche Integration von LLMs erfordert einen strategischen Ansatz, der Leistung, Kosten und Benutzerfreundlichkeit in Einklang bringt. Hier sind die wichtigsten Erkenntnisse:
- API-Auswahl: Wählen Sie die API basierend auf Ihren spezifischen Anforderungen
- Modell-Strategie: Implementieren Sie eine Cascading-Strategie für optimale Kosteneffizienz
- Prompt Engineering: Investieren Sie Zeit in die Optimierung Ihrer Prompts
- Kostenmanagement: Setzen Sie Budgetgrenzen und implementieren Sie Caching-Strategien
- Kontinuierliche Verbesserung: Analysieren Sie die Leistung und passen Sie Ihre Strategie an